Czech Large Language Model CSMPT-7B
In March 2024, we publicly released the first Czech-only large language model csmpt7b. Our language model was trained on dataset collected from Czech internet, Internet Archive, and also on publicly available historical texts ranging from the year 1850 until now. The texts were transcribed using our Pero OCR system.

Training Procedure
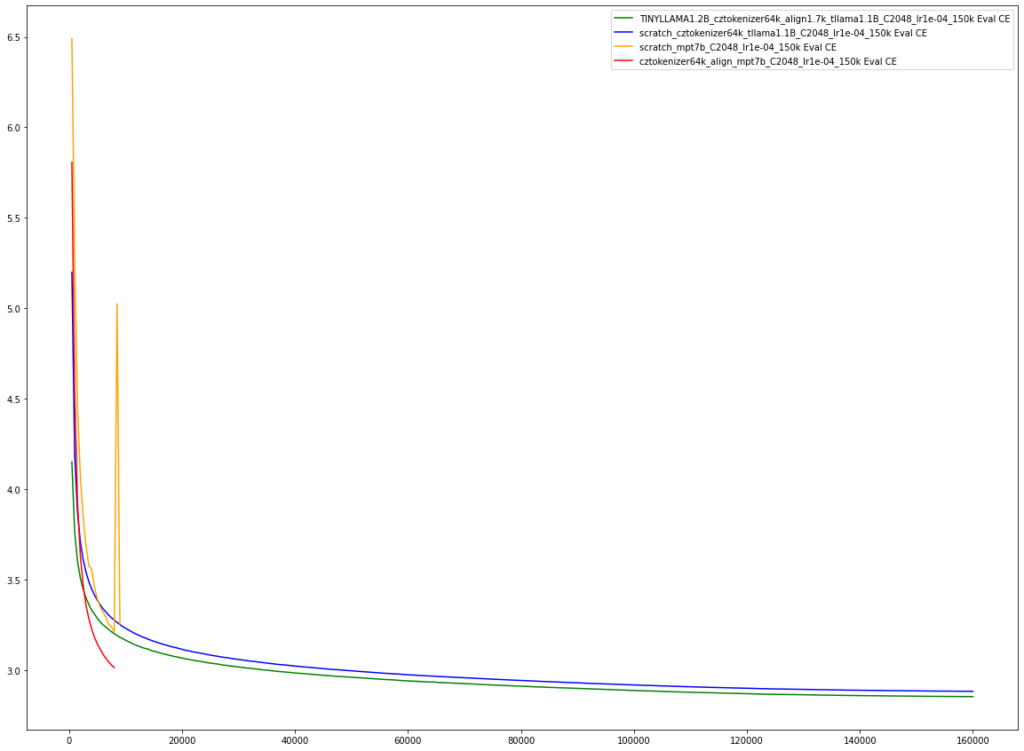
Our language model follows procedure, which has never before been tested for the model of its size (both parameter-wise and datawise). It is initialized from a model trained on English language (MPT-7B), and its vocabulary (a set of terms the model understands) is replaced from English to Czech one. Each such term needs to be encoded by vector representation, so that the neural network can “understand” what it refers to. As we have a set of new terms, some of the pretrained English representations corresponding to English terms, are copied in-between the new Czech representations corresponding to terms (Dog→Pes) in our Czech vocabulary. Our results suggest that, after such initialization, the model is able to benefit from its English pretraining, by achieving a better cross-entropy metric than the newly initialized model (trained from “scratch”).
Czech Language Model Family
CSMPT7B isn’t the only thing we released. We also released the largest available clean czech training dataset BUT-Large Czech Collection, and two smaller language models, fine-tuned from their English counterparts: GPT-2-XL (1.5B) and CsTinyLLAMA (1.2B).
What is such a Language Model Good For?
Firstly, such language models can be used out-of-box for directly solving certain tasks through the mechanism called “few-shot learning”. Furthermore, the models can be finetuned for the target tasks, where the datasets are available, or instruction-fine tuned — which means they are finetuned to perform any task described in the user instruction.
In the next phase of our work, we plan to utilize our LLM for semantic enrichment of historical documents, on tasks such as document retrieval, question answering, entity/relation tagging, or general chat-bot assistance for anything related to historical document analysis.